RAG vs CAG: Choosing the Right Approach for Your LLM Application
Introduction
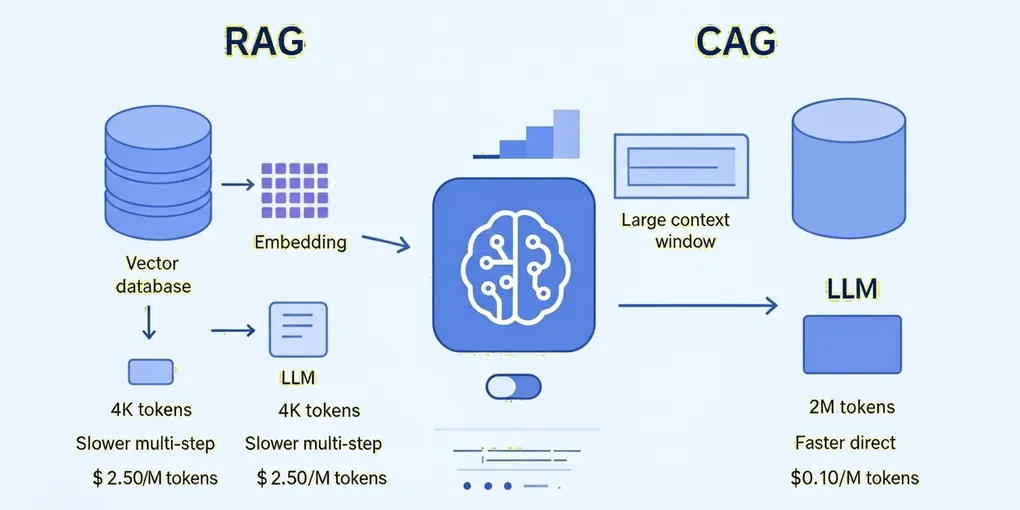
The landscape of large language model (LLM) applications is evolving rapidly, and two approaches have emerged for incorporating external data: RAG (Retrieval Augmented Generation) and CAG (Cage Augmented Generation). Understanding when to use each approach can significantly impact your application’s performance, cost, and complexity.
RAG: The Traditional Approach
RAG has been the most popular method for bringing external resources to LLMs. The process works like this:
- Data Preparation: Convert your data into a vector database with small chunks
- Query Processing: Transform user questions into embeddings
- Retrieval: Search the vector database for the most relevant chunks (top-k results)
- Context Injection: Feed both retrieved chunks and user question to the LLM
RAG Challenges
While RAG is powerful, it comes with several challenges:
- Setup Complexity: Requires vector database implementation and maintenance
- Latency Issues: Time spent on embedding generation and retrieval
- Retrieval Accuracy: Ensuring retrieved chunks contain complete information
- Chunking Problems: Simple chunking (e.g., 500 characters) can break up code examples or complex information
CAG: The New Paradigm
CAG represents a fundamentally different approach. Instead of retrieving portions of data, CAG pre-loads the entire database into the model’s context window.
// Example CAG implementation with Gemini 2.0const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: `Based on the following documentation, help me generate a request to scrape this website using firecrawl:
${fullDocumentationText}
User query: ${userQuery}` }] }]});The Context Window Revolution
This approach only became feasible recently due to dramatic improvements in context windows:
- 24 months ago: ~4,000 tokens (limiting CAG to small documents)
- Today: 100-200,000 tokens for most flagship models
- Gemini models: Up to 2 million tokens (488x improvement!)
This translates to approximately 1.5 million words - more than most novels!
CAG Advantages
1. Simplicity
CAG eliminates the complex RAG pipeline:
// RAG: Complex setup requiredconst vectorStore = await createVectorStore(documents);const relevantChunks = await retrieveChunks(query, vectorStore);const response = await model.generateResponse(query, relevantChunks);
// CAG: Simple and directconst response = await model.generateResponse(query, fullDocuments);2. No Retrieval Accuracy Issues
Since the entire dataset is in context, the model can access all information without worrying about retrieval completeness.
3. Better for Complex Queries
Complex questions that might require information from multiple sources become much easier to handle.
Cost and Performance Improvements
Recent model improvements have made CAG increasingly viable:
Gemini 2.0 Flash
- Input cost: Only $0.10 per million tokens (96% cheaper than some alternatives)
- Performance: Can process large documentation sets in 2-3 seconds
- Example: Processing entire Firecrawl API documentation (~27 pages) costs ~$0.006
Building an MCP Server with CAG
Let’s build a practical example using CAG to create an MCP server that retrieves code examples from documentation:
Step 1: Setup and Dependencies
import { GoogleGenerativeAI } from '@google/generative-ai';import { Firecrawl } from '@firecrawl/firecrawl';import Headon from 'headon'; // For logging and monitoring
const genAI = new GoogleGenerativeAI(process.env.GOOGLE_AI_API_KEY);const firecrawl = new Firecrawl(process.env.FIRECRAWL_API_KEY);const headon = new Headon(process.env.HEADON_API_KEY);Step 2: Filter Relevant Documentation
// Get all sub-pagesconst allPages = await firecrawl.mapUrl('https://docs.firecrawl.dev');// Filter for API reference pagesconst apiPages = await model.filterRelevantPages(allPages, 'API reference');// Result: Reduced from 153 to 27 relevant pagesStep 3: Batch Scrape and Cache
// Scrape all relevant pagesconst markdownContents = await firecrawl.batchScrapeUrls(apiPages);// Cache locally for future useawait saveToLocalCache('firecrawl-docs', markdownContents);Step 4: Generate Response with Full Context
const response = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: `Based on the complete Firecrawl documentation provided below, help me generate the correct API request:
${markdownContents}
User request: ${userQuery}` }] }], // Log to Headon for monitoring httpOptions: headon.getHTTPOptions()});When to Use Each Approach
Choose RAG when:
- Your dataset is too large for model context windows
- You need sub-second response times
- Cost optimization is critical
- You have diverse, constantly updating data
Choose CAG when:
- Your dataset fits within context windows (up to 2M tokens for Gemini)
- Simplicity is preferred over complex retrieval systems
- You need maximum accuracy for complex queries
- You’re working with static or slowly changing documentation
Advanced CAG Optimizations
1. Hybrid Approach
For very large datasets, combine both methods:
// Use traditional search to pre-filterconst relevantSections = await searchByMetadata(query, fullDataset);// Then apply CAG on filtered resultsconst response = await model.generateResponse(query, relevantSections);2. Parallel Processing
// Process multiple data chunks in parallelconst parallelResults = await Promise.all( dataChunks.map(chunk => model.generateResponse(query, chunk)));// Use another model call to synthesize resultsconst finalResponse = await model.synthesizeResponses(parallelResults);3. Context Caching (Future)
Gemini supports context caching for repeated queries on the same large dataset, which will further improve performance.
Monitoring and Optimization with Headon
Track your LLM application performance:
// All requests automatically loggedconst response = await model.generateContent({ contents: [...], httpOptions: headon.getHTTPOptions() // Auto-logging enabled});
// Monitor in Headon dashboard:// - Cost per request// - Latency patterns// - User interaction patterns// - Performance optimization opportunitiesConclusion
CAG represents a paradigm shift in LLM application development. With dramatically improved context windows and reduced costs, it’s becoming the preferred approach for many use cases. The simplicity of implementation and elimination of retrieval accuracy issues make it particularly appealing for documentation-based applications and code generation tasks.
As context windows continue to expand and costs decrease, CAG will likely become the default approach for an increasing number of LLM applications, while RAG remains valuable for extremely large-scale or real-time applications.
The future belongs to developers who can leverage the full power of these expanded context windows to build more accurate, simpler, and more capable AI applications.


